Representación del conocimiento a través de Entidades Digitales
Coordinador: Andrés Montoyo Guijarro
Tarea B.1. Entidades Digitales, identificación y especificación
El objetivo de esta tarea es la identificación y especificación de entidades digitales. Para ello, son necesarios los siguientes pasos: i) identificar las propiedades de las entidades digitales; ii) especificar sus propiedades y metadatos en formatos estandarizados de ontología; y iii) realizar la especificación final de Core Ontology y ontologías específicas.
Tarea B.1.1 Modelo de Entidad Digital
Para construir un modelo de Entidad Digital, se deben realizar las siguientes tareas. En primer lugar, se define un modelo para integrar entidades digitales; en segundo lugar, es necesario desarrollar herramientas para crear el modelo de integración; y, en tercer lugar, se evalúa el modelo de integración. El esquema de la figura refleja la arquitectura general involucrada en la construcción de una entidad digital a partir de una entidad. Este esquema se interpreta como un modelo construido de abajo hacia arriba, transfiriendo información al siguiente nivel, hasta que la entidad digital esté completamente construida. A continuación, se muestra una definición de cada bloque:
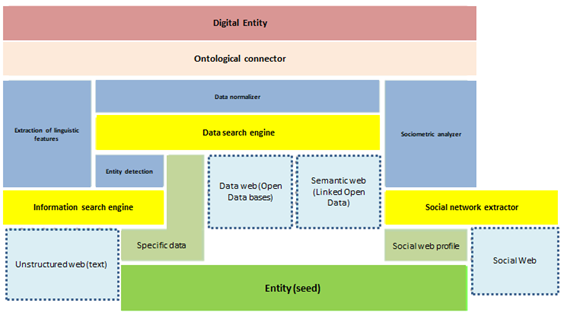
- Entidad (semilla): datos a partir de los cuales comenzamos a construir una entidad digital. Puede ser un nombre, una cuenta en una red social o un conjunto de datos conocidos.
- Datos específicos: datos específicos que conocemos sobre la entidad.
- Perfil web social: perfiles que conocemos, en los que la entidad existe en las redes sociales. Los tres bloques anteriores son los datos de partida para construir una entidad digital.
- Buscador de información: toma como entrada los datos específicos conocidos de la entidad y realiza un proceso de búsqueda de información en la web. Este proceso involucra tanto la recuperación de información no estructurada (textos) como el filtrado y extracción de textos.
- Buscador de datos: busca información sobre datos estructurados, ya sean bases de datos abiertas o de la web semántica (bases de conocimiento sobre la web de datos enlazados).
- Extractor de redes sociales: genera un gráfico de relaciones con otras entidades para su posterior análisis a partir de la información de la web social (comunidades y redes sociales).
- Detección de entidades: obtiene datos específicos a partir de información no estructurada. Estos datos también alimentan al buscador de datos.
- Extracción de rasgos lingüísticos: a partir de los textos se generan los rasgos lingüísticos que se consideran relevantes, como el cálculo del modelo lingüístico, vectores de palabras, modelado de tópicos, etc.
- Normalizador de datos: normaliza (formatea) todos los datos encontrados y su representación.
- Analizador sociométrico: calcula las medidas sociométricas que se estiman oportunas sobre la entidad en su grafo social, por ejemplo centralidad, densidad, agrupación, etc.
- Conector ontológico: a partir de toda la información generada en los niveles anteriores, se agregan los metadatos correspondientes y se generan las propiedades de acuerdo a la ontología definida (basada en la ontología core). Este módulo también es responsable de mantener la concordancia ontológica (coherencia) entre todas las entidades generadas por el modelo.
Tarea B.1.2. Gestión inteligente de información web heterogénea
Los objetivos de esta tarea son los siguientes: analizar y adaptar los recursos, herramientas y técnicas existentes; desarrollar nuevos recursos, herramientas y técnicas necesarias para nuestros sistemas; para detectar, identificar, extraer y monitorear temas y entidades nombradas; gestionar entidades de fuentes heterogéneas; extraer rasgos lingüísticos, sociales y subjetivos; y, por último, enriquecer las entidades digitales con datos subjetivos, datos abiertos y datos vinculados
Tarea B.1.3. Seguimiento y Detección de sujetos y Entidades Nombradas
El reconocimiento, clasificación y seguimiento de las entidades a lo largo del tiempo se convierte en un elemento crucial de este proyecto, ya que constituye una de las fuentes de información prioritarias para la caracterización de las entidades digitales.
En esta tarea se monitorean las fuentes de información, por ejemplo los medios de comunicación o una cuenta de Twitter, y se analizan los textos para determinar los diferentes hilos temáticos que se desarrollan. La información está categorizada por tema (detección) y una representación en línea de tiempo permite analizar una entidad digital en un período determinado. Esto es importante ya que la difusión de noticias o actualizaciones puede ser de interés para varios actores (gestión de emergencias, detección de temas de actualidad o difusión viral de información).
Tarea B.2. Enriquecimiento semántico
Considerando los datos abiertos y vinculados, se realizan las siguientes acciones:
- Diseñar la estructura de la ontología donde se incluya toda la información dependiente del lenguaje.
- Rellenar la ontología utilizando herramientas semiautomáticas (clasificadores humanos) en los dominios especificados. Para ello se llevarán a cabo las siguientes subacciones:
- Crear una interfaz de usuario para completar la ontología. Para facilitar la poblacion de ontologías es necesario proporcionar a los expertos una interfaz de usuario inteligente.
- Insertar manualmente instancias base en ontologías a través de la interfaz de usuario integrada. A través de las interfaces de usuario, los expertos insertarán datos en las ontologías específicas para cada dominio.
- Desarrollar y aplicar métodos semiautomáticos para seguir poblando las ontologías. A partir de las interfaces de usuario y la base de conocimiento agregada en las ontologías, se aplicarán nuevos métodos de inferencia para poblar las ontologías.
- Filtrar datos erróneos por métodos automáticos y semiautomáticos.
Tarea B.3. Descubrimiento del conocimiento a través de entidades digitales
El objetivo principal de esta tarea es el desarrollo de diferentes técnicas, recursos y herramientas TLH dirigidas a modelar entidades digitales, sus relaciones en las redes sociales y su evolución en el tiempo. Estas herramientas se integran en una plataforma tecnológica que permite la detección y extracción de relaciones semánticas entre entidades digitales. Esta tarea obtiene información integrada de diferentes fuentes (datos no estructurados, estructurados y abiertos), y determina la calidad, coherencia y veracidad de estas relaciones. El objetivo final del modelo es predecir comportamientos futuros de las entidades digitales, así como prevenir situaciones de alto riesgo antes de que ocurran.
Tarea B.3.1. Identificación de Fuentes de Información
Esta tarea se centrará en identificar las fuentes de datos e información requeridas para el proyecto, respecto a los diferentes dominios y escenarios. También realizaremos un estudio y análisis exhaustivo de los datos abiertos enlazados de varios sitios web. Esto proporcionará una fuente de información valiosa, y en muchos casos de gran calidad, y deberá incorporarse e integrarse en los sistemas desarrollados como un valor añadido.
Tarea B.3.2. Identificación de Relaciones entre Entidades Digitales
El tratamiento adecuado de las interacciones entre entidades digitales requiere un estudio previo del tipo de relaciones semánticas subyacentes entre ellas. Algunos ejemplos son relaciones de dependencia (para que exista la identidad A, debe existir la identidad B), relaciones de dominio (el valor de la identidad A determina el dominio de la identidad B), relaciones lógicas (exclusión mutua, por ejemplo), entre otras. Un análisis detallado de las fuentes de información, textos, documentos digitales, metadatos y otras fuentes dentro de la identidad digital nos permitirá definir y caracterizar estas relaciones básicas.
Tarea B.3.3: Detección de Relaciones Semánticas entre Entidades
Esta tarea tiene como objetivo definir y desarrollar algoritmos y técnicas para detectar posibles relaciones semánticas entre diferentes entidades digitales. Estos algoritmos tienen en cuenta características comunes y el contexto en el que fueron analizados. Para ello, se utilizarán técnicas de similitud semántica para generar diferentes interpretaciones en base a reglas o patrones del lenguaje que determinen la identificación de relaciones y mapeo de entidades digitales. Esta tarea también explorará las redes semánticas de las entidades digitales para que podamos estudiar diferentes mecanismos y estructuras, no solo para la detección de relaciones, sino también para la identificación de grupos de entidades relacionadas semánticamente.
Tarea B.3.4: Técnicas de detección de veracidad, análisis de emociones y subjetividad
El objetivo de esta tarea es estudiar y desarrollar técnicas que permitan establecer medidas de credibilidad para determinar la veracidad de la información, contemplada desde diferentes puntos de vista: la credibilidad del medio de comunicación (canal) y del contenido, así como de la fuente de información. La credibilidad del mensaje hace referencia a la percepción de la veracidad del mensaje, teniendo en cuenta factores como la calidad o la precisión. Este problema se puede abordar mediante el análisis de las bases de conocimiento disponibles para las entidades y las relaciones entre ellas. Se utilizarán medidas de credibilidad con respecto a los medios, mensajes y fuentes de información para clasificar la información por grados de veracidad.
Tarea B.3.5: Técnicas para la Predicción de Comportamientos Futuros
Construir un repositorio de entidades digitales y las diferentes relaciones entre ellas nos permite recopilar una gran cantidad de datos individualizados sobre las interacciones entre estas entidades a lo largo del tiempo. El análisis de distintas relaciones concretas, la agrupación de entidades y la contrastación de las relaciones existentes nos permite llegar a interesantes conclusiones sobre el comportamiento de un determinado colectivo, e incluso predecir comportamientos a partir del estudio de situaciones previas.
Resultados de este módulo:
- Tecnologías para la identificación de entidades
- Tecnologías para el descubrimiento de entidades digitales y sus atributos
- Recursos y tecnologías para la representación del conocimiento de las entidades digitales
- Recursos y tecnologías para el enriquecimiento semántico de las entidades digitales con enlace de datos externo
- Repositorio de entidades digitales y relaciones entre ellas
- Tecnologías para establecer la evolución de estas entidades y sus relaciones en el tiempo